MinerU 是一款专注于从复杂PDF文档、网页和电子书中高效提取内容的一站式文档处理平台,MinerU主要由两大模块组成:Magic-Doc:处理网页和多种电子书格式的提取工作;Magic-PDF:专注于PDF文档的智能解析与转换。MinerU 自2024年7月正式推出以来,凭借其高效准确的解析能力和开源易用的特性,迅速获得了广大用户和大模型开发者的青睐。上线仅五个月,其GitHub星标数就接近2.5万,被开发者誉为”大模型时代的文档提取、转换神器“。
为什么选择MinerU?——五大核心优势解析
1. 强大的格式支持能力|全格式兼容【PDF/Word/PPT/图片等 一网打尽,拖拽/截图/批量上传,一键导入】
MinerU支持处理多种文档类型,包括但不限于:
- PDF文档:学术论文、教科书、研究报告、财务报告、考题等
- 电子书:epub、mobi等多种流行格式
- 网页内容:可直接解析网页中的文本、图像、表格和公式信息
特别值得一提的是,MinerU不仅能处理标准PDF,还能应对扫描版PDF和加密版文档的解析挑战,这在同类工具中实属难得。
2. 精准的内容提取与结构保留
与普通PDF转换工具不同,MinerU能够智能识别并保留原文档的结构,包括:
- 标题层级关系
- 段落分布
- 列表项目
- 多栏排版布局
同时,它能自动去除干扰元素,如页眉、页脚、脚注和页码,确保提取出的内容干净整洁,便于后续使用。
3. 多元素精准解析【精准定位图表/公式等复杂元素,多模态解析精准提取】
MinerU真正强大的地方在于其对文档中多种元素类型的识别能力:
- 文本内容:支持84种语言识别(最新版本支持176种语言),自动检测并转换乱码
- 数学公式:可检测文档中的行内公式和块公式,并将其转换为LaTeX格式
- 表格数据:能识别复杂表格结构,转换为HTML或Markdown格式
- 图片内容:提取文档中的图像并保留在输出结果中
这种多模态解析能力使得MinerU特别适合处理学术论文、技术文档等包含复杂内容的材料。
4. 灵活的输出选项|多场景极速输出【Markdown/JSON/LaTeX/HTML等一键转换、适配机器学习、大模型语料生产、RAG等场景】
根据用户不同需求,MinerU提供多种输出格式:
- Markdown:适合写作、笔记和内容发布
- JSON:便于程序进一步处理和分析
- HTML:适合网页展示
- LaTeX:满足科研人员的专业需求
用户还可以获取包含丰富信息的中间格式文件,如layout.json(版面识别结果)、model.json(元素识别结果)等,为深度开发提供可能。
5. 跨平台与开源优势
MinerU支持Windows、Linux和macOS三大操作系统,无论是个人电脑还是服务器环境都能运行。作为开源工具,它允许开发者自由查看和修改代码,也意味着用户可以完全掌控自己的数据,不必担心隐私泄露问题。
MinerU的核心功能详解
1. PDF文档的智能处理
作为MinerU的核心功能,Magic-PDF模块提供了全方位的PDF解析能力:
结构保持与清理
- 自动识别并删除页眉、页脚、页码等非主要内容
- 保留原始文档的标题层级、段落结构和列表格式
- 智能处理单栏和多栏排版,输出顺序符合人类阅读习惯
内容提取与转换
- 文字提取:支持84种(最新版176种)语言识别,自动处理乱码
- 公式转换:将数学公式精准识别为LaTeX代码
- 表格处理:将PDF中的表格转换为HTML或Markdown格式
- 图片提取:保留文档中的图像并嵌入输出文件
特殊场景支持
- 扫描版PDF:自动检测并应用OCR技术提取文字
- 加密文档:支持部分加密PDF的解析
- 大体积文件:优化了处理算法,能高效处理数百页的长文档
2. 网页与电子书的内容提取
Magic-Doc模块扩展了MinerU的应用场景:
网页内容提取
- 精确解析网页文本、图像、表格和公式
- 保留原文结构和语义关系
- 支持从动态加载的网页中提取内容
电子书转换
- 支持epub、mobi等多种电子书格式
- 完整提取文本和图像内容
- 保持原书的章节结构和阅读顺序
3. 多语言支持
MinerU的多语言识别能力是其一大亮点:
- 支持中文(简体和繁体)、英文、俄语、日语、韩语等176种语言
- 自动检测文档语言类型
- 混合语言文档处理能力
这一特性使其成为处理国际化文档的理想工具,特别适合跨国公司、外语学习者和多语言研究者。
MinerU的使用方式
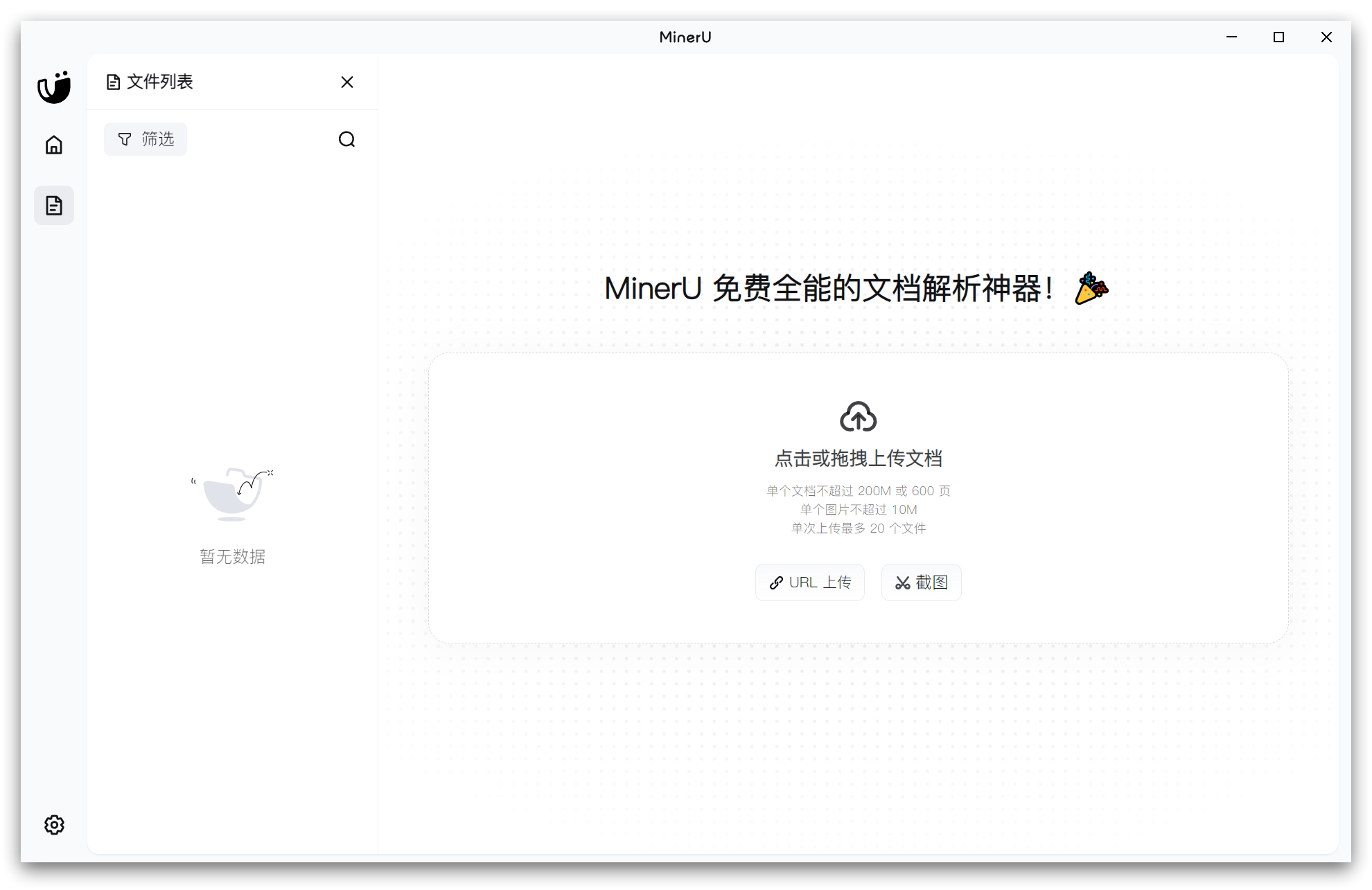
1. 图形界面客户端(适合普通用户)
为了让非技术用户也能轻松使用,MinerU提供了跨平台的桌面客户端:
- 支持Windows、macOS和Linux系统
- 下载安装即可使用,无需编程知识
- 操作简单:拖放文件到界面或输入URL即可开始转换
- 支持PDF、Word、PPT等多种文档格式
- 提供多种识别模式和语言配置选项
MinerU与同类工具的比较
为了帮助用户理解MinerU的独特价值,以下是它与常见文档处理工具的对比:
| 特性 | MinerU | 常规PDF转换器 | 专业OCR软件 |
|---|---|---|---|
| 结构保留 | 优秀 | 一般 | 较差 |
| 公式处理 | 支持LaTeX输出 | 不支持 | 不支持 |
| 表格识别 | 高精度 | 低精度 | 中等精度 |
| 多语言支持 | 176种语言 | 有限 | 视软件而定 |
| 开源免费 | 是 | 部分 | 通常收费 |
| 输出格式多样性 | 多种 | 有限 | 通常单一 |
| 网页/电子书支持 | 有 | 无 | 无 |
从对比可见,MinerU在功能全面性和处理精度上具有明显优势,特别是对于学术和技术文档的处理能力远超普通转换工具。
MinerU作为一款国产开源的文档解析工具,凭借其全面的功能、精准的解析能力和便捷的使用方式,已经成为许多用户处理复杂文档的首选。无论是学术研究者、内容创作者、企业员工还是开发者,都能从中找到适合自己的应用场景。
获取方式
官方网站
https://github.com/opendatalab/MinerU
网盘下载
https://pan.quark.cn/s/8cddb4f7cfcb
更多趣软酷站请访问:
https://www.gewuzhizhi.vip/software-store/all-software-store/internet-resources
★★★ 强烈推荐 ★★★ 点击下图,500+常用办公精品软件一键直达!

© 版权声明
文章版权归作者所有,未经允许请勿转载。