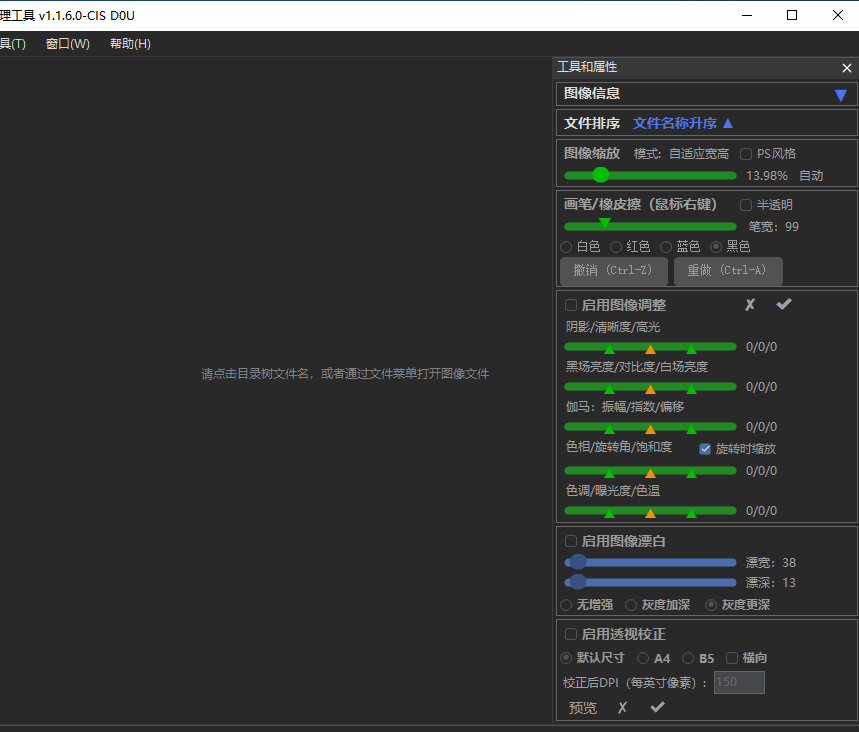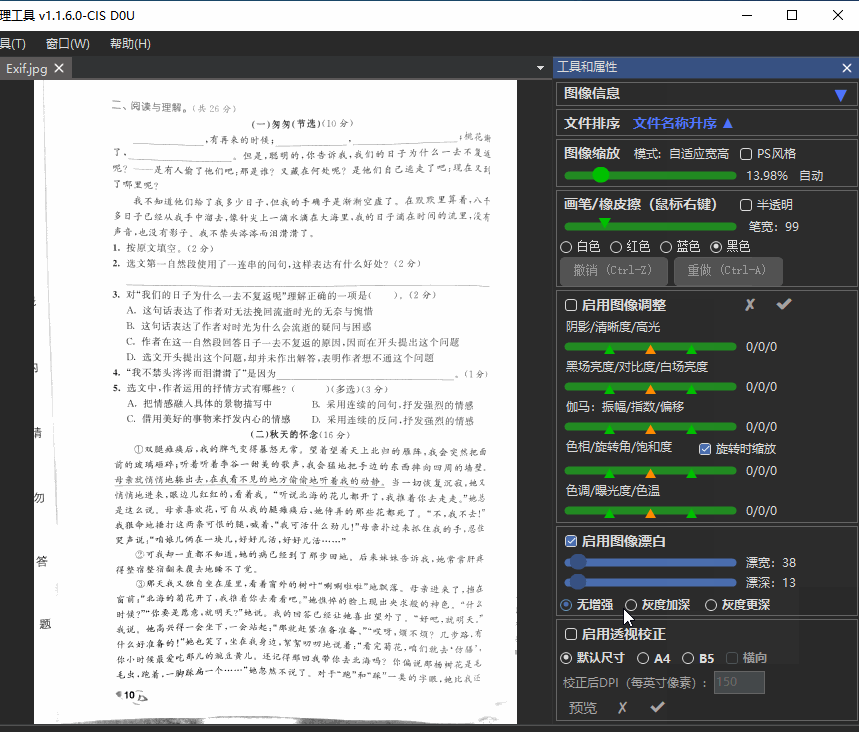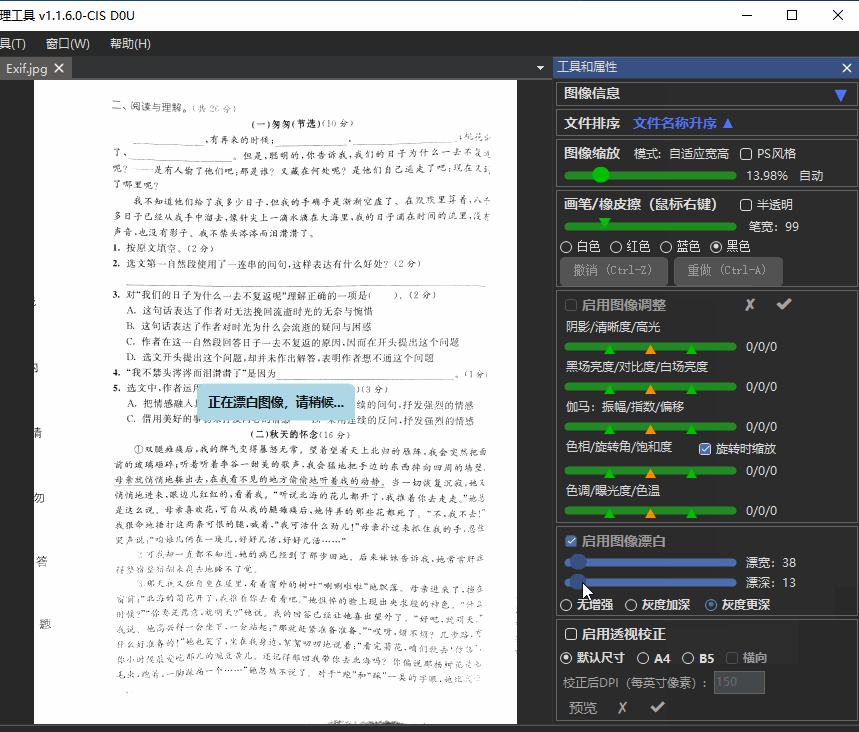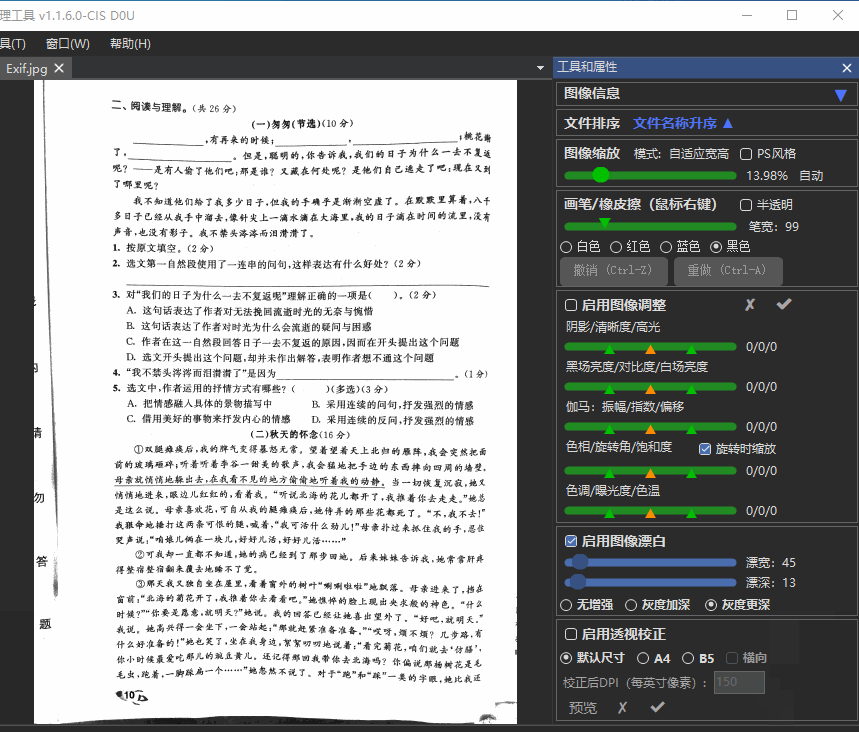
Versatile OCR Program 是一款专为机器学习优化的强大 OCR 工具,能精准提取复杂结构化数据。支持多语言文本(包括日语、韩语和英语,可扩展支持其他语言),支持 JSON 和 Markdown 格式输出,包含数学表达式、表格摘要和图像说明,准确处理包含密集科学内容和丰富视觉元素的考试风格 PDF,自动为视觉内容生成自然语言描述,并为提取的元素添加语义标注和上下文解释,适合制作高质量的 ML 训练数据集。
经过测试,在 EJU 生物学和东京大学数学等真实学术数据集上,达到 90-95% 的高准确率。
J.Cling 推荐拓展:
- iOS OCR Server – iPhone 手机变成强大的本地OCR识别工具
- PillOCR OCR公式识别工具 – 基于大模型api的OCR神器
- Umi-OCR – 免费开源本地离线批量文字识别工具
主要功能特点
- 优化机器学习训练:提取的元素(如图形、表格和图形)会进行语义标注,并附上上下文解释。这包括自动生成视觉内容的自然语言描述(例如,“该图形展示了有丝分裂的四个阶段”),以增强下游模型训练。
- 多语言支持:支持日语、韩语和英语,并可以轻松定制以支持其他语言。
- 结构化输出:生成适用于 AI 的 JSON 或 Markdown 格式输出,包括数学表达式的人类可读描述、表格摘要和图形标题。
- 高精度:在 EJU 生物学和 UTokyo 数学等真实世界学术数据集上达到 90-95%以上的准确率。
- 复杂布局支持:准确处理包含密集科学内容、公式密集段落和丰富视觉元素的考试风格 PDF。
- 技术栈:DocLayout-YOLO、Google Vision API、Gemini Pro Vision、MathPix OCR、OpenAI API、OpenCV 等。
官方使用说明
以下是使用真实材料(2017 年 EJU 生物学和 2014 年东京大学数学)生成的系统实际输出示例,包括英文翻译的语义上下文和提取的数据。
数学输入

输出

英文翻译输出
问题 1. 考虑底边为 1 的正方形底面的长方体 OABC–DEFG。点 P、Q、R 分别位于线段 AE、BF 和 CG 上,且四点 O、P、Q、R 位于同一平面上。设四边形 OPQR 的面积为 S。此外,设∠AOP 为α,∠COR 为β。(2) 如果α + β = 1 且 S = S,求 tan α + tan β的值。另外,如果α ≤ β,求 tan α的值。
[图片开始]
图像描述:该图像展示了长方体 OAB–CDEFGQ。每个顶点都用字母标记。在面 OAB 上标出了角度α。平面 ORPQ 与长方体相交并被突出显示。线段 RC 位于面 ODCG 上,线段 PB 位于面 ABFQ 上。
教育价值:这张图片通过可视化 3D 几何和截面来增强空间推理能力。它帮助学习者理解平面几何、立体形状、空间可视化和角度等概念。
相关主题:立体几何、截面、棱柱面、三角形、空间推理
考试相关性:这类问题出现在入学考试中,例如:
- 使用角度α计算 ORPQ 的面积
- 求 OR、RP、PQ、QO 的长度
- 确定 ORPQ 与棱镜面的夹角
- 在坐标系中定位点 P、Q、R
- 计算棱镜各部分的体积/面积
- 根据约束预测形状
- 绘制棱柱的形状
生物学输入

输出

英文翻译输出
问题 39. 这张照片展示了洋葱根尖的有丝分裂过程(体细胞分裂)。细胞 A–D 处于不同的分裂阶段。将阶段(前期、中期、后期、末期)与每个细胞对应起来,并从选项①–⑧中选择正确的组合。
图像描述:这张图像显示了在显微镜下观察到的植物细胞分裂过程。各种细胞处于不同的有丝分裂阶段,包括染色体在中心对齐(中期)、分离到两极(后期)或形成子细胞核(末期)。
A – 看起来处于后期
B – 可能处于末期
C – 前期或中期
D – 中期
教育价值:这有助于学生直观地理解有丝分裂的过程,巩固细胞分裂阶段及其特征的知识。它与 DNA 复制、癌症生物学和遗传学等生物学概念相联系。
相关主题:有丝分裂、细胞周期、前期、中期、后期、末期、DNA 复制
考试相关性:这张图片用于以下问题:
- 将 A、B、C、D 与适当的细胞分裂期匹配
- 描述每个阶段的特点
- 解释细胞分裂的重要性
- 讨论有丝分裂中的错误如何导致遗传疾病
| 前期 | 中期 | 後期 |
|---|---|---|
| A | C | D |
| A | D | B |
| B | C | C |
| B | D | C |
| C | A | D |
| C | D | A |
| D | A | B |
| D | C | A |
摘要:每个选项(①–⑧)对应 A、B、C、D 到前期、中期和后期的特定映射。
教育价值:理解有丝分裂中的时间性转变和表格中的数据组织。增强数据解读、模式识别和分析能力。
相关主题:数据分析、表格解读、生物数据分类
使用流程
- 步骤 1 – 初始 OCR 提取 运行 ocr_stage1.py 从输入 PDF 中提取原始元素(文本、表格、图形等)。此步骤执行布局检测并存储中间结果(例如,坐标、裁剪图像、原始内容)。
- 步骤 2 – 语义解释与最终输出 运行 ocr_stage2.py 处理中间数据并将其转换为结构化、人类可读的输出。这包括生成自然语言解释、摘要,以及将内容组织成 AI 准备好的格式(JSON/Markdown)。
获取方式
官方网站
https://github.com/ses4255/Versatile-OCR-Program
网盘下载
https://pan.quark.cn/s/2dfffea61cb9
更多AI软件请访问:
https://www.gewuzhizhi.vip/software-store/all-software-store/ai-software
★★★ 强烈推荐 ★★★ 点击下图,500+常用办公精品软件一键直达!
© 版权声明
文章版权归作者所有,未经允许请勿转载。