Paper Burner X 是集文献识别、翻译、阅读与智能分析于一体,在浏览器上打开就能用的开源工具,作为一个前端Agent 智能分析系统,可自主调用工具进行多步推理,还能翻译长论文,保留公式、图表等复杂格式。致力于将复杂的文档处理、翻译和分析流程整合到单一、流畅的体验中,经常需要进行精细、长文本阅读的研究人员和深度学习者不妨试试。
J.Cling 推荐拓展:
- YouMind – 口碑极佳的浏览器拓展丨一键收藏AI分析整理任意文章
- Glass – 开源免费的桌面AI工具|智能监听分析屏幕和音频内容
- PDF Document Layout Analysis – 开源免费PDF文档分析提取工具
- Dedoc – 将任意格式自动转为统一格式|提取分析PDF文档等
- Hammer PDF – 智能AI学术PDF信息提取分析工具
- NativeMind 本地化AI助理 – 对话|内容分析|搜索翻译|写作辅助
- MinerU – 免费全能的PDF文档解析提取工具

目前实现了:
- 前端 Agent 驱动的智能检索: 我们在前端实现了一个 Agentic RAG 系统。通过赋予 AI 全局的文章结构 和一系列工具(如
grep,vector search,fetch等等),AI 能够自主决策、多步推理,并在长文本中实现复杂的分析和信息提取任务。 - 高性能批量处理: 支持多种文档格式(PDF/DOCX/EPUB 等)和代码库的直接导入。利用并发 OCR 和翻译,并结合术语库(支持数万词条快速匹配),显著提升了文献处理效率。
- 高可扩展性与本地化: 目前所有数据均在浏览器本地,支持用户接入自定义 AI 模型端点,并提供了配套的 OCR Server 和 Docker 部署选项(开发中),让用户未来可以实现完全离线的本地化使用。
该项目扩充了诸多阅读/AI工具上的便利,但如果您需要一个轻量化的文档处理工具,也欢迎使用 Paper Burner , baoyu 的原分支。
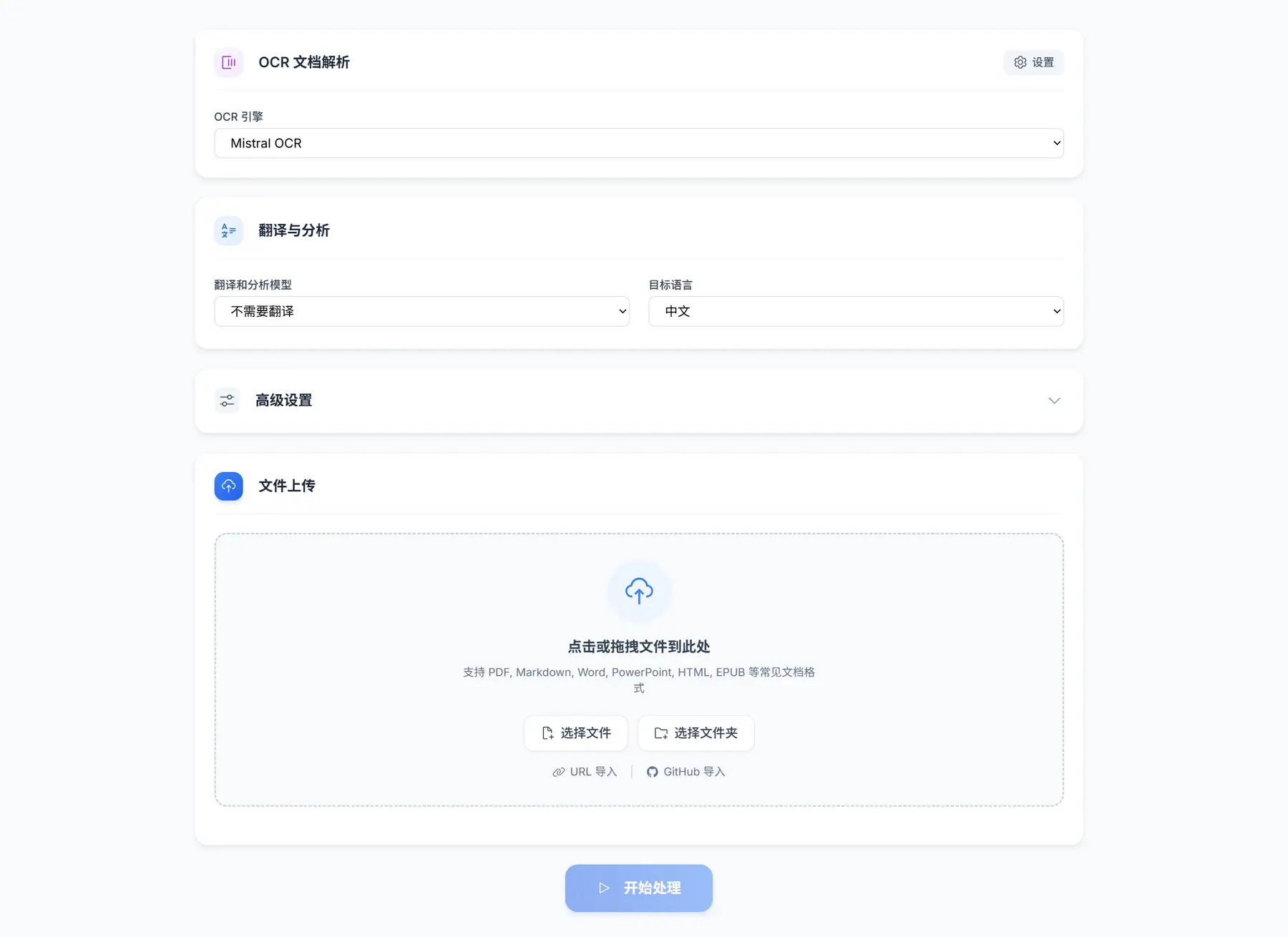
主要功能特点
1. ⚡ 极速并发翻译
- 多文件并发处理 – 一次上传多个文件,自动排队处理
- 高速并发翻译 – 理想情况下,长论文翻译仅需几十秒
- 自定义并发数 – 可配置文件处理和翻译任务的并发数量
- 提示词池机制 – 智能健康管理提示词,保证翻译质量
- 文件夹批量导入 – 支持整个库/文件夹翻译,保留文件夹层级
2. 🔧 灵活的配置管理
- 术语库系统 – 维护多套术语库,自动注入翻译提示,保持术语一致性
- 自定义提示词 – 支持自定义翻译 Prompt,满足客制化需求
- 提示词池生成 – AI 自动生成提示词变体,保证核心需求不变
- 模型自动检测 – 通过
/v1/modelsAPI 自动检测可用模型 - 多 Key 轮询 – 支持多个 API Key 轮询使用,提高稳定性
- 配置导入导出 – 方便迁移和备份配置
3. 📖 增强的阅读体验
- 历史记录面板 – 基于 IndexedDB 存储,支持原文/译文/对比模式
- 公式与表格渲染 – 完美支持 LaTeX 公式、图片、表格渲染
- 分块对比 – 原文与译文智能对齐,段落级精准对比
- 目录导航 (TOC) – 快速浏览文档结构,实现内容间快速跳转
- 沉浸式阅读 – 桌面端沉浸模式,所有要素集中在一个画面
- 标注与高亮 – 字级高亮和标注,支持多种颜色
4. 🤖 智能文档分析
- AI 聊天助手 – 对长文档进行提问和分析,支持流式输出
- 快捷指令 – 预置学术相关问题,快速提问
- 思维导图生成 – 自动生成文档思维导图
- 流程图生成 – 支持 Mermaid 流程图生成和编辑
- 对话导出 – 将 AI 对话内容快速导出为图片
- 图片上传 – 支持上传图片进行多模态对话
5. 📁 多格式支持
支持导入:
- PDF / Markdown / TXT / DOCX / PPTX / HTML / EPUB
支持导出:
- HTML / PDF / DOCX / Markdown(支持图片嵌入或链接)…
官方使用说明
核心优势:
- ⚡ 极速翻译 – 并发处理,长论文仅需数十秒
- 🎨 完美排版 – 保留公式、图表、格式
- 🤖 智能分析 – AI 助手、思维导图、流程图生成
- 🔒 隐私安全 – 纯前端模式,数据完全本地化
- 🐳 灵活部署 – 支持 Vercel 静态部署和 Docker 完整部署
一体化的文档处理引擎
我们为工具打造了一个强大的“入口”,使其能够轻松消化各种来源的知识。
- 广泛的格式支持: 能够处理 PDF、DOCX、PPTX、EPUB、Markdown 甚至代码注释等多种格式,并支持导出为 DOCX、MD 等常用格式。
- 智能导入与处理: 不仅支持本地文件上传,更可一键从 GitHub 仓库或任意 URL 导入内容,自动完成解析。PDF可以使用OCR (支持mineru/doc2x等) 与翻译引擎,并实现保留原文格式翻译功能(基于mineru,目前优化中,并会支持更多模型)。
- 术语备择库: 进行了性能优化,支持一次性导入数万条术语并进行快速匹配。
- 支持自定义模型端点,可以支持检测、多key、快捷导出等机制,使用灵活。
为深度阅读优化的交互体验
- 沉浸式对照阅读: 提供智能对齐的段落级原译文对照、文档结构目录(TOC)、高亮与标注功能,先进行无障碍的阅读,再进行AI总结。
- 增强学术内容展示: 针对学术场景,特别优化了复杂公式的渲染。
- 结构化信息提取: 内置了“文献矩阵”等实用工具,能够将非结构化的论文内容,智能提取为清晰的结构化数据,方便进行横向对比和分析。
不止于问答:前端 Agent 驱动的智能分析
- 我们在纯前端环境中,实现了一个长文本Agent。少量文本下,将使用全量的策略;而当提供长文本时候,使用长文本Agent。
- 赋予 AI 全局视野: 我们为 AI 构建了“分层意群/地图”,让它在处理长文本时拥有对全文结构的整体认知。
- 为 AI 配备工具箱: 我们给予 AI 一系列工具,如精确匹配的
grep、向量搜索vector search、内容抓取fetch等。AI 会根据你的问题,自主分析并决定调用哪种工具组合来寻找最佳答案。 - 上述皆在纯前端实现,浏览器打开即用
项目正在活跃地迭代
- 完全本地化部署: 正在开发Docker 部署方案,还提供了可自托管的 OCR Server,最终目标是让用户可以完全在离线环境中使用全部功能。
- 从单文档到多文档: 下一个里程碑是将能力从分析单篇文献,扩展到处理多篇文献,并基于此开发能自动生成文献综述的 综述 Agent,成为真正的 AI 研究助理。
https://github.com/Feather-2/paper-burner-x/blob/main/deploy/DEPLOYMENT_GUIDE.md
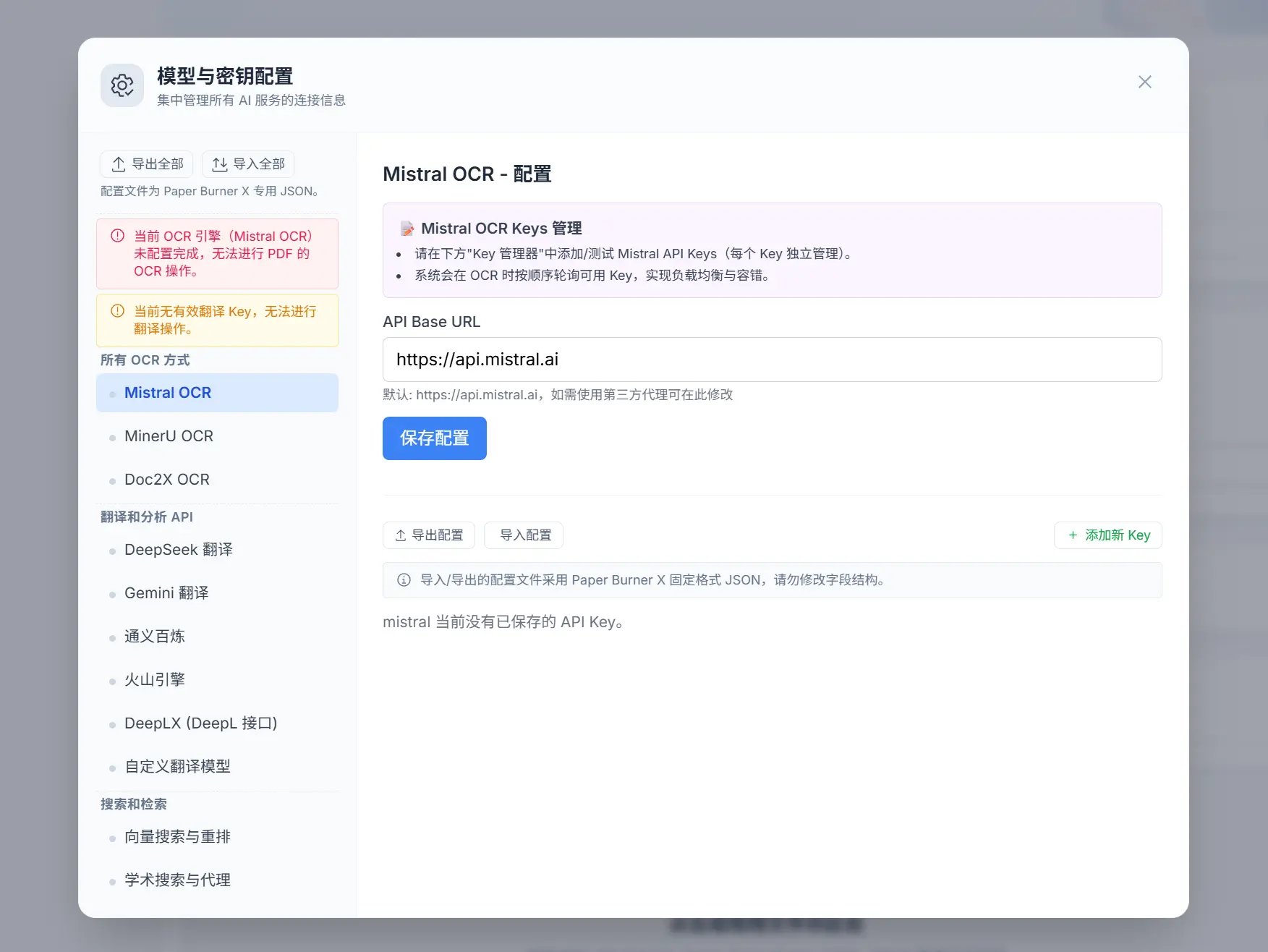
获取方式
官方网站
https://github.com/Feather-2/paper-burner-x
https://paperburner.viwoplus.site/views/landing/landing-page.html
网盘下载
https://pan.quark.cn/s/74877ce01055
更多AI软件请访问:
https://www.gewuzhizhi.vip/software-store/all-software-store/ai-software
★★★ 强烈推荐 ★★★ 点击下图,500+常用办公精品软件一键直达!
© 版权声明
文章版权归作者所有,未经允许请勿转载。