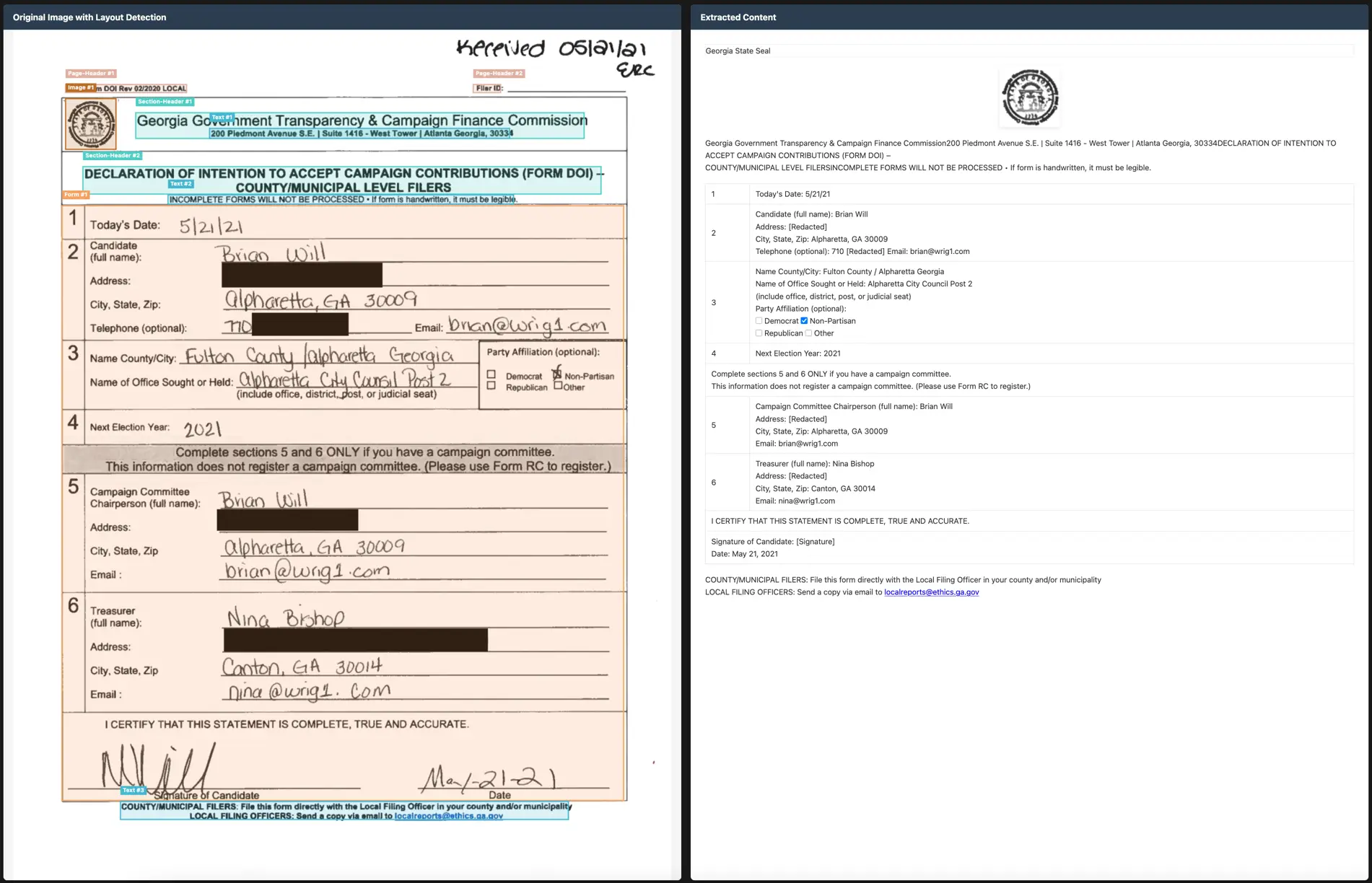
Chandra 是一款基于深度学习的开源OCR模型,支持将图像和PDF高精度地转换为HTML、Markdown 或 JSON等结构化格式。它在完成文本提取的同时,能够出色地保留原始文档的布局信息,这对于处理包含页眉页脚、复杂表格、数学公式乃至手写内容的文档至关重要。
此外,该工具支持超过40种语言的识别,并针对手写体、表单(包括复选框)、以及学术文献中的数学公式做了专项优化。它提供本地(HuggingFace)和远程(vLLM服务器)两种部署模式,并配备了命令行工具与交互式Web界面,便于集成与批量处理。
J.Cling 推荐拓展:
- Texo – 数学公式OCR识别工具|一键转为LaTeX代码
- Text Grab – 无需联网的开源OCR文字识别工具
- Versatile OCR Program – 90-95%高准确率的OCR文字识别工具
- DeepSeek OCR APP – 基于 DeepSeek-OCR 开发AI OCR识别工具
- DeekSeek-OCR Dockerized API:高质量PDF转Markdown开源工具
主要功能特点
- 将文档转换为带有详细布局信息的 Markdown、HTML 或 JSON
- 良好的手写支持
- 精确重建表单,包括复选框
- 对表格、数学和复杂布局的良好支持
- 提取图像和图表,包含标题和结构化数据
- 支持40多种语言
- 两种推理模式:本地(HuggingFace)和远程(vLLM 服务器)
官方使用说明
见网盘
更新日志
v0.1.7
- 正确渲染 pdf 图像
获取方式
官方网站
https://github.com/datalab-to/chandra
网盘下载
https://pan.quark.cn/s/ffe950d20d3e
更多AI软件请访问:
https://www.gewuzhizhi.vip/software-store/all-software-store/ai-software
★★★ 强烈推荐 ★★★ 点击下图,500+常用办公精品软件一键直达!
© 版权声明
文章版权归作者所有,未经允许请勿转载。