做自媒体、剪辑短视频、写文案、做播客、做影视解说的朋友,大概率都踩过 AI 配音工具的坑,可以试试 软件格律诗 今天给大家分享的这款全能语音软件 OmniVoice Studio, 完全本地运行,不用充值订阅、不用上传音频到第三方服务器,实时听写、零样本语音克隆、电影级视频配音全部桌面端就能完成,646 种语言全覆盖,不管 Windows、Mac 还是 Linux 都能直接装。
之前我一直用线上语音工具,痛点真的堆了一堆。主流的 ElevenLabs 按月收费,最低每月 5 美元起步,字符还要额外计费,做长视频配音开销很大;所有音频文件全部上传云端处理,做内部项目、私密解说视频,隐私完全没保障;只支持 32 种语言,小语种、冷门方言根本没法做。还有不少国产配音工具,克隆声音需要上传几十秒样本,训练等十几分钟,导出视频还要二次转码,操作链条又长又繁琐;实时听写要么收费,要么每分钟限制字数,办公开会记录特别受限。
它是开源免费的 ElevenLabs 平替,整套流程全部在本地硬件运行,没有任何云端上传动作,不用 API 密钥、不用注册账号,个人永久免费,企业仅需商业授权即可商用,完全没有使用次数、字符、时长限制。
核心实用功能,每一项都直击日常需求
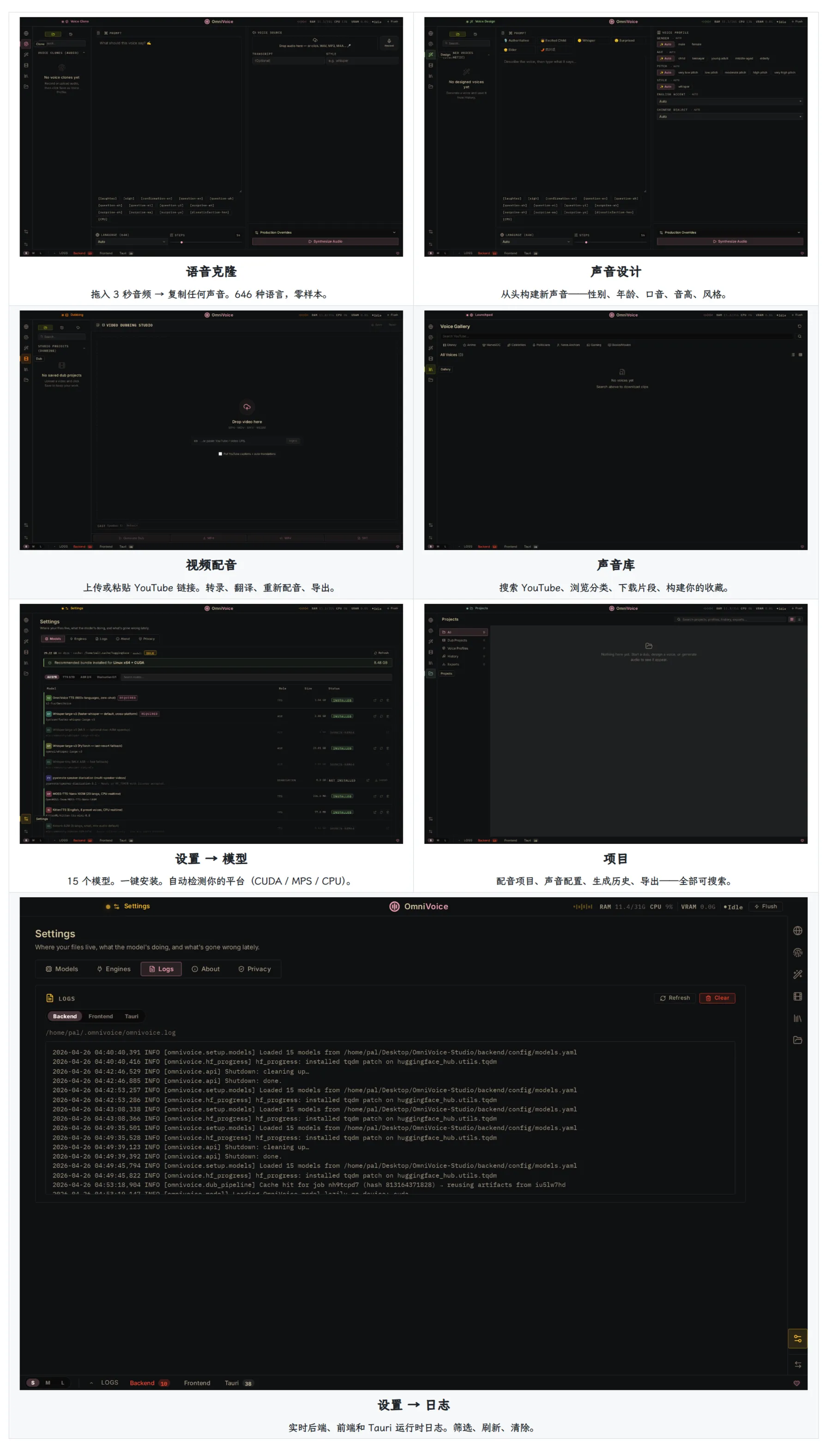
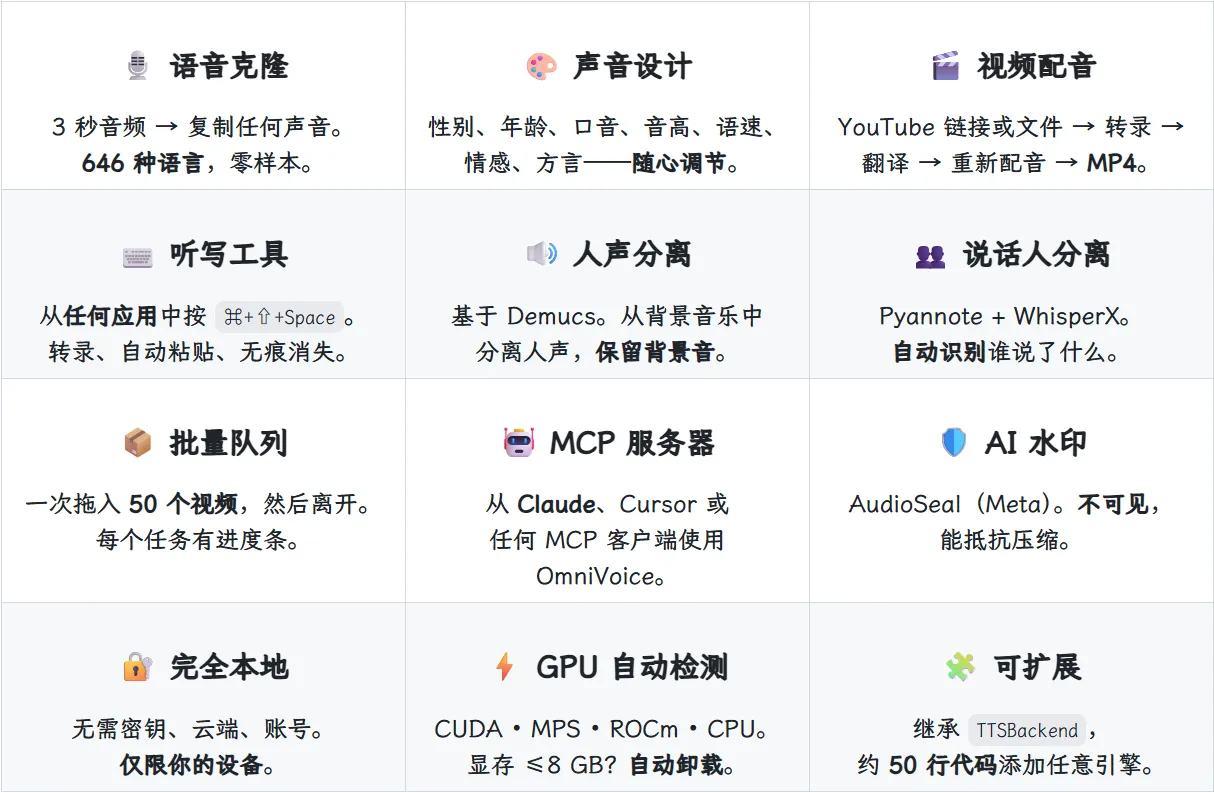
3 秒零样本语音克隆,646 种语言随意切换
只需要一段 3 秒干净音频,就能完整复刻任何人的声线,零样本无需训练,上传素材立刻生成语音。覆盖 646 种语言,不管各国小语种、国内各类方言都能适配,克隆完成后还能跨语言生成配音,用中文样本也能生成日语、英语、俄语旁白。
日常做解说、虚拟主播、有声书都够用,生成的人声自然流畅,没有机械电子音,还支持 A/B 双轨试听对比,方便挑选最合适的音色版本。
自定义声音设计,从零打造专属声线
不用参考音频也能自制全新人声,性别、年龄、口音、音高、语速、情绪、方言全部可调。想做沉稳中年旁白、温柔少女音、厚重播音腔、外国口音台词,拖动参数就能实时预览,调整好的音色一键存入本地声音库,后续项目直接调取,不用反复重新调节。
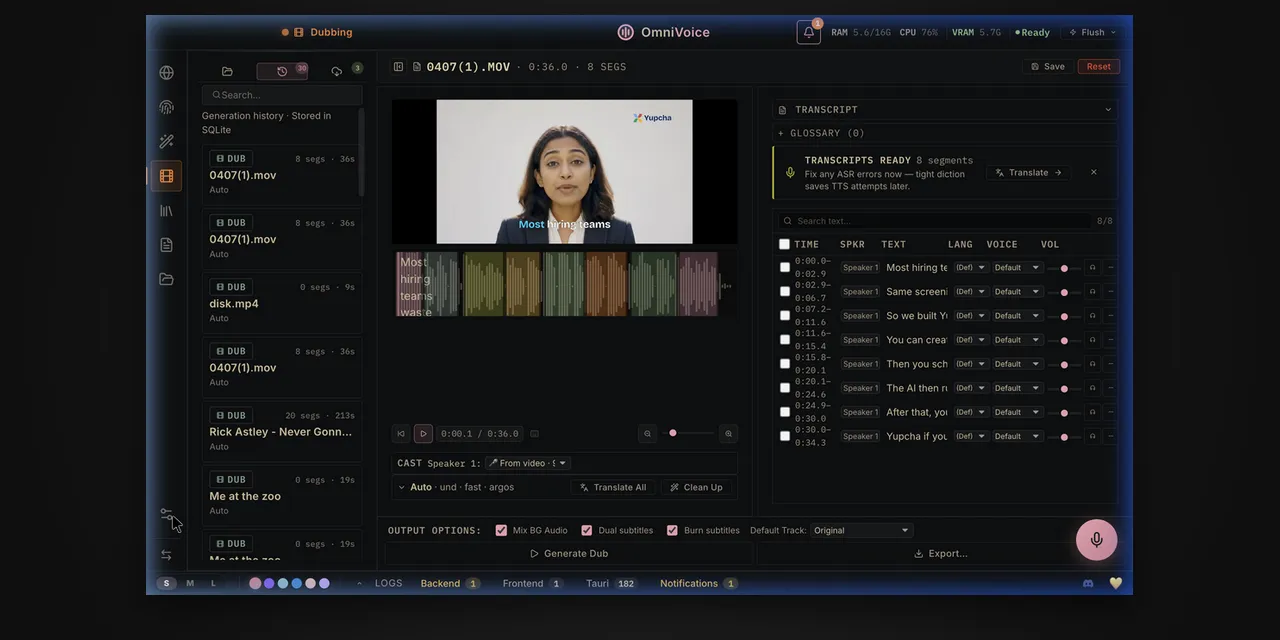
全链路视频自动配音,本地一键导出成片
支持上传本地视频,也能直接粘贴 YouTube 链接处理,整套流水线全自动完成:语音转录原文、多语种翻译、人声分离、重新配音、封装导出 MP4。 内置 Demucs 人声分离模型,能把原视频人声和背景音乐、音效分开,完整保留原背景音,只替换配音;搭配 Pyannote 说话人分离,自动识别视频里多个人物,给不同角色分配独立克隆声线,做多人对话视频不用手动分段剪辑。批量队列功能支持一次拖入 50 条视频后台处理,不用守在电脑前等待。
全局实时听写工具,系统热键一键转文字
设置快捷键⌘+⇧+Space(Windows 替换对应组合键),任意软件界面都能启动听写,说话实时转文字自动粘贴,浮动窗口无痕隐藏,开会记录、采访录音转文稿、写脚本都很省事。底层搭载 WhisperX 模型,99 种语言精准识别,断句、字词对齐清晰,导出 SRT、VTT 字幕文件直接适配剪辑软件。
完整音频处理配套工具,一站式音频工作室
除核心配音克隆外,自带大量实用音频功能:
- 批量音频导出,可单独分离人声、背景音乐轨道保存;
- 逐段音量增益调节,0-200% 区间精细控制,适配广播级音质;
- Meta AudioSeal 隐形 AI 水印,生成音频自带不可溯源标记,抵抗压缩剪辑,可后台检测音频来源;
- 完整项目管理,所有配音工程、音色、生成记录本地保存,支持检索回溯;
- 实时运行日志面板,查看模型加载、生成进度,排查故障更简单。
全平台适配,低配电脑也能流畅运行
支持 macOS、Windows、Linux 三大系统,提供 DMG、MSI、AppImage、deb 四种安装包,一键安装自动配置 Python 环境与模型。硬件适配非常友好:最低 8G 内存、4G 显存就能启动,显存≤8G 时软件自动将 TTS 模型卸载至 CPU,不会卡顿;无独立显卡依靠 CPU 也能运行,只是生成速度稍慢;自动识别 CUDA、Apple Silicon MPS、AMD ROCm 加速,有显卡的设备生成效率直接提升三倍以上。
纯本地存储,隐私安全性拉满
这是我最看重的一点,所有音频、视频、音色、项目配置全部保存在本机,不会向外部服务器传输任何数据,断网状态下全部功能正常使用。不会采集浏览记录、音频内容,无第三方数据共享渠道,处理公司内部素材、私密访谈、原创内容完全不用担心泄露,对比所有线上配音工具,隐私优势无可替代。
多 TTS 引擎拓展,自由切换语音模型
内置多款主流 TTS 引擎,默认 OmniVoice 模型支持 600 + 语种,同时兼容 CosyVoice 3、VoxCPM2、MLX-Audio 等开源模型,在设置面板一键切换,也可自行开发接入新引擎,仅需 50 行代码完成适配,开源架构自由度极高。
简单安装方式,三种渠道按需选择
- 桌面客户端(新手首选):GitHub Releases 页面下载对应系统安装包,双击启动自动下载模型与运行环境,macOS 出现损坏提示仅需一行终端命令修复,Windows 首次启动等待 5-10 分钟自动配置依赖;
- Docker 部署:一行命令拉取镜像,支持 CPU、NVIDIA GPU 两种运行模式,适合工作室多设备统一部署;
- 源码运行:克隆仓库后执行简单指令启动前后端,适合开发者二次修改、拓展功能。
获取方式
官方网站
https://github.com/debpalash/OmniVoice-Studio
网盘下载
© 版权声明
文章版权归作者所有,未经允许请勿转载。